









內容目錄
ZK 協處理器想解決什麼問題?
使用場景:產品數據搜集與計算
現有的 Web3 產品,總覺得好像少點什麼功能,就是跟 Web2 產品有落差,像是自動推薦、忠誠度計畫、精準行銷等,這些在傳統軟體已經行之有年的標配,為何在 Web3 的產品中沒有看到?
舉個更具體的例子,某用戶上 Netflix 看影集,後台會搜集用戶所有的觀看紀錄與操作行為,藉由搜集這些數據,經過演算法計算後找到用戶可能喜愛的內容,最後進行個性化的推播與廣告。
但是在 Web3 生態中,某用戶在 Uniswap 常常使用穩定幣交易對,將 USDT 兌換成 USDC,為何 Uniswap 的介面無法將這名用戶常使用的交易對自動顯示呢?
其實上述問題出在「數據」,Web2 的產品能有系統地搜集並對數據進行計算,就像是搜集用戶觀看紀錄,但是 Web3 產品則不行,就算只是簡單的交易紀錄。
可能有讀者會問「交易紀錄不是本來就在區塊鏈上嗎?為何會無法讀取?」其實還真的不行,又或者更精確地說:成本很高、不然就要承擔風險。
問題一:區塊鏈虛擬機不適合大量運算
要做到上述應用場景,需要做到許多計算資源,再以 Uniswap 的例子來說,如果要做到「歷史交易對自動顯示在首頁,方便用戶更快完成目的。」會需要以下努力:
搜集用戶交易紀錄
比較各種交易紀錄使用次數並選出最高者
執行
最後一部執行基本上現在智能合約就做得很好了,有問題的是前兩步驟。
針對第一步,雖然交易紀錄都在練鏈上沒錯,但是虛擬機跟區塊鏈歷史帳本是兩回事,虛擬機要讀取歷史帳本會需要非常多的燃料費用。且每次要調用就用重新讀取一次或是儲存,但不管什麼做法都非常耗費資源,不適合在分散式虛擬機使用。
第二步則是資料的處理,雖然相對簡單,但因為在 EVM 之上也同樣需要大量資源去計算,若問題再難一點 (例如分析用戶觀看紀錄與觀看時間決定等等要推播的內容),那麼絕對是專案無法負擔的成本。
問題二:套用外部數據有信任假設問題
「如果鏈上無法計算,那就鏈下處理吧!」這是非常合理的思路,包含 Etherscan、Dune、DeBank 等服務都是使用此方式,確實可以解決許多問題。
像是區塊鏈空投,判定規則就算是公開的,但實際上進行篩選行為還是由團隊負責,最後在公開結果,但這之間存在信任假設 (怎麼知道團隊沒有作弊),也難怪每次空投社群常常出現爭議與怨言。更別說真的有問題的數據會造成什麼後果。
因此,鏈下計算這條路在許多應用場景似乎也不可行。
Web3 數據的兩難
這樣就會出現兩難,若直接抓取數據並計算成本太高昂,但如果使用鏈下計算結果則增加信任假設。也難怪目前沒有原生使用 Web3 數據的服務出現。
因此,市場出現 ZK 協處理器的概念嘗試解決此問題,同時做到鏈下計算但又可以不增加信任假設,完美地解決此問題。
ZK 協處理器介紹
將計算工作從 EVM 獨立出來
ZK 協處理器 (ZK Coprocessor) 又稱為 ZK 輔助處理器,其核心概念是將 EVM 不擅長計算的部分拉出來,藉由鏈下計算與零知識證明,做到同時高效率且無需信任,近一步增加區塊鏈的效率。
協處理器的名稱其實就是從 CPU 與 GPU 之間的關係而來的,GPU 將 CPU 不擅長大量針對圖像運算的工作拿來做,藉由這種輔助專業分工,最大化電腦效率。而區塊鏈其實也就是一種去中心化的電腦,當然也可以使用類似的作法。
ZK 協處理器如何避開上述問題
協處理器抽象來看,主要就是把兩件事做好:
數據讀取:讀取區塊鏈帳本中的交易紀錄,並透過 ZK 證明數據真偽。
數據計算:根據數據與需求做出相應的計算,並再次透過 ZK 證明結果真偽。
最後再把數據回傳給智能合約,智能合約可以藉由零知識證明以低成本的方式快速驗證與使用,最大化增加執行效率。
ZK 協處理器與 Rollups 提升的效率不同
ZK 協處理器更多的是在提升前段的過程,也就是數據搜集與數據處理的效率,而 Rollups 則是提升數據處理與執行的效率,兩者並不是競爭者,更像是互補的關係。
ZK 協處理器實作專案介紹
ZK 協處理器目前主流的專案包含 Brevis、Herodotus、Axiom 等,核心運作概念如同上述內容,不過實作上的手段有些許差異。
Brevis
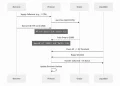
Brevis 是由 Celer Network 相同團隊成員創辦,該服務架構可以分為三部分:
zkFabric:負責搜集區塊鏈上的資料,並將區塊練頭資訊計算零知識證明。
zkAggregatorRollup:負責儲存資料並傳輸給區塊鏈上的智能合約,包含 zkFabric 蒐集到的資料與 zkQueryNet。
zkQueryNet:處理 Web3 智能合約所需要的數據與運算。
Brevis 設計架構 (資料來源)
Axiom
Axiom 的服務是提供無需信任的區塊鏈查詢服務,與上述中心化的鏈下查詢架構不同,Axiom 所提供的資料都可以藉由零知識證明確認資料正確性。
ZK 協處理器不是唯一解
ZK 協處理器可以解決 Web3 數據搜集與計算的問題,對於提升產品使用體驗與精準行銷都是非常關鍵的。
但其實如果要解決「區塊鏈上的數據運算」,還有其他解決方式,例如 Smart Layer 就是利用附加外部數據的方式,可以做到相同的事情,但其信任假設風險則取決於 Smart Layer 網路本身的安全性。
若是相對不重要的資訊,當然也可以直接仰賴鏈下計算,而不用所有資訊都要完全無需信任,重要的還是解決什麼問題。