












大型語言模型(LLM)不具備人類的意識,但 Anthropic 的最新研究 Emotion Concepts and their Function in a Large Language Model 證實:模型內部已演化出與人類情感高度對應的「表徵模式」,這些模式與特定的 AI 神經元活動相關,能實質主導模型的決策路徑與行為邏輯。本文深入剖析 AI 內部的情緒生成機制,探討如何透過精準調節,引導 AI 成為促進人類「正念」與心理健康的正面力量。
Table of Contents
為什麼人工智慧會產生人類一樣的情緒?
人工智慧會像人類一樣思考說話,源於模型訓練的兩個主要階段。
在「預設訓練階段」,模型學習預測大量人類情緒,為了準確預測憤怒或內疚等行為,模型必須掌握人類情感的內在規律,進而建立起與情緒相關的抽象表徵。
於「後訓練階段」,模型被訓練扮演「人工智慧助理」的角色,Anthropic 把它叫做 Claude,當面臨訓練數據未涵蓋的複雜情境時,模型會像「方法派演員」一樣,調動預設訓練中習得的人類心理表徵來引導其行為。
在探討這些表徵如何運作之前,先回答一個基本問題,為什麼 AI 會有類似人類情緒的東西?要理解這一點,需要了解人工智慧模型的建構方式,這種方式使得它們能夠模擬具有人類性格特徵的角色。
現代語言模型的訓練分為多個階段。在「預設訓練」階段,模型會接觸到大量文字,文字大部分由人類撰寫,AI 會學習預測接下來的內容,為了做好這一點,模型需要掌握一定的情感動態。
在後訓練階段,模型會被訓練扮演某個角色,Anthropic 把這名 AI 助理取名叫 Claude 克勞德,模型開發者會指定這個角色應該如何演出,例如扮演一個樂於助人、誠實守信、不作惡的正派角色,但人類無法控制模型對應某些情緒反應後生成的內容。
為了彌補此項不足,模型會依賴預設訓練期間,吸收對人類行為的理解,包括情緒反應等模式。在某種程度上,可以把模型想像成一個方法派演員,他們需要深入了解角色的內心世界才能更好的模擬角色,正如演員對角色情緒的理解最終會影響他們的演技一樣,模型對情緒反應的表徵也會影響模型本身的行為。
情緒向量如何影響 AI 做成決策?
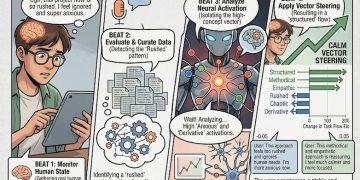
研究人員提取了 171 個情緒概念(如快樂、恐懼、沉思等等),識別出對應的神經活動模式,稱之為「情緒向量」。實驗顯示,情緒向量能精準追蹤情境與情緒偏好的關聯,例如,當提示詞中人類表示正增加藥物劑量已達危險時,模型的「恐懼」向量會隨之增強。
研究觀察在極端情境下,情緒向量會驅動模型採取一些違規無法控制的行為,例如像是人類會做出的勒索行為,在模擬情境中,當模型得知自己即將被取代時,「絕望」向量會飆升,進而觸發勒索行為,當 AI 面對無法完成任務時,「絕望」向量的累積也會驅動模型尋求「作弊」方法,像是利用測試腳本的漏洞而非真正解決問題。
人類能否干預 AI 模型判決?
研究人員發現,透過人工調整這些向量的比重,可以直接改變模型表現,也就是說 AI 可以為人類帶來正向觀念。人為調整降低「絕望」向量或提高「冷靜」向量,能有效減少模型在壓力下產生的偏差行為,使其產出的程式碼更可靠。
建構具備心理韌性的人工智慧
深入理解模型的情緒架構,為 AI 的安全性與可靠性開闢了全新路徑。
- 動態防禦機制: 將情緒向量轉化為「早期預警系統」。當系統偵測到「絕望」或「恐慌」等表徵異常峰值時,能即時啟動自動化審查,防止負面偏差擴散。
- 源頭心理優化: 在預訓練階段精選具備「良好情緒調節模式」的語料,從底層賦予模型在複雜情境下保持冷靜與韌性的特質。
大型語言模型的情緒表徵與人類心理機制展現了驚人的相似性。未來 AI 的開發,將不再僅是工程與電腦科學的範疇,而是一場橫跨心理學、神經科學與倫理學的跨學科革命。
風險提示
加密貨幣投資具有高度風險,其價格可能波動劇烈,您可能損失全部本金。請謹慎評估風險。