


Anthropic 於 2024 年 11 月正式發表了一項名為 Model Context Protocol(MCP)的開源標準,目標是為 AI 模型與外部系統之間的連接建立統一的通訊協議。這項標準被業界比喻為「AI 界的 USB-C」,因為它解決的問題本質上與 USB-C 統一充電介面的邏輯相同 — 讓所有 AI 應用程式透過同一套標準化的接口,與各種外部工具、資料庫和服務溝通,而不需要為每一個整合對象重新開發客製化的連接方式。
MCP 的出現標誌著 AI 應用開發進入一個新階段。過去幾年,大型語言模型的能力突飛猛進,但它們與真實世界系統的互動方式卻始終缺乏統一標準。MCP 正是為了填補這個缺口而誕生的。本文將完整介紹 MCP 的運作原理、核心架構、支援生態系以及實際應用方式,幫助開發者與關注 AI 發展的讀者全面理解這項協議的意義與潛力。
Table of Contents
MCP 解決了什麼問題
在 MCP 出現之前,AI 應用程式要與外部系統互動面臨一個根本性的挑戰:每一個 AI 工具與每一個外部服務之間的整合,都需要從頭開發專屬的連接邏輯。假設市場上有 10 個 AI 應用程式,同時有 10 個外部服務需要串接,理論上就需要開發 100 組不同的整合方案。這種 M×N 的組合爆炸問題,不僅浪費大量開發資源,也讓整個生態系的發展速度受到嚴重制約。
具體來說,這些問題體現在幾個層面。首先是重複勞動。每當一個新的 AI 應用程式想要支援 GitHub 整合,開發團隊就必須從零開始撰寫與 GitHub API 對接的程式碼,即使其他 AI 應用程式已經做過完全相同的事情。其次是維護成本。當外部服務的 API 更新時,所有依賴該 API 的客製化整合都需要同步修改。第三是品質參差不齊。不同開發者實作的整合方案,在安全性、效能和穩定性方面往往存在顯著差異。
更深層的問題在於,這種碎片化的整合方式嚴重限制了 AI 應用程式的實用性。一個 AI 助理如果只能讀取文字輸入、產出文字回覆,卻無法存取使用者的檔案、查詢資料庫或操作開發工具,那它能提供的價值就被大幅縮限。使用者期待 AI 能夠真正融入工作流程,而不是作為一個孤立的對話窗口存在。
MCP 的提出正是要從根本上改變這個局面。透過建立一套標準化的通訊協議,MCP 將 M×N 的複雜度降低為 M+N — 每個 AI 應用程式只需實作一次 MCP 客戶端,每個外部服務只需建置一個 MCP 伺服器,兩者之間就能透過統一的協議自由互通。
USB-C 類比的深層意義
「AI 界的 USB-C」這個比喻並非隨意選取,它精確地捕捉了 MCP 的核心設計理念。回顧 USB-C 出現之前的消費電子市場,每家手機廠商都有自己的充電接口 — Apple 用 Lightning、Samsung 用 Micro USB、部分筆電用 DC 圓孔接頭。消費者的抽屜裡堆滿了各種不同的充電線,出門時還得煩惱要帶哪幾條。
USB-C 的出現改變了這一切。一個統一的接口標準,讓所有裝置都能使用同一條線充電、傳輸資料、甚至輸出影像訊號。裝置製造商不再需要設計自己的專屬接口,配件廠商也不需要為每款裝置生產不同的線材。整個生態系因此變得更加高效、開放且對使用者友善。
MCP 在 AI 領域扮演的角色與此完全對應。在 MCP 之前,每個 AI 應用程式與每個外部服務之間的連接,就像是一條專用的充電線 — 只能用在特定的組合上。MCP 則提供了一個通用的「接口」,讓任何支援 MCP 的 AI 應用程式都能與任何提供 MCP 伺服器的外部服務連接,不需要額外的客製化開發。
這個類比也延伸到了更深的層面。就像 USB-C 定義了電力傳輸、資料傳輸和影像訊號的標準規範一樣,MCP 也定義了三種核心的互動模式 — 工具呼叫、資源存取和提示範本。這三種「通道」涵蓋了 AI 應用程式與外部系統互動的主要需求,確保協議的通用性和完整性。
三大核心原語
MCP 的設計圍繞三種核心原語(Primitives)展開,每一種都對應 AI 與外部系統互動的一種基本模式。理解這三種原語,就能掌握 MCP 的運作邏輯。
| 原語 | 英文名稱 | 功能描述 | 典型用途 |
|---|---|---|---|
| 工具(Tools) | Tools | 可執行的函式,AI 模型可以主動呼叫來完成特定動作 | 發送訊息、建立檔案、查詢 API、執行程式碼 |
| 資源(Resources) | Resources | 結構化的資料來源,AI 模型可以讀取但不會修改 | 讀取檔案內容、查詢資料庫紀錄、取得系統狀態 |
| 提示範本(Prompts) | Prompts | 預先定義的互動範本,引導 AI 模型以特定方式處理任務 | 程式碼審查範本、文件摘要範本、翻譯工作流程 |
工具(Tools)
工具是 MCP 中最直覺的原語。它代表一個具體的、可執行的函式,AI 模型可以決定何時以及如何呼叫它。每個工具都有明確的名稱、描述和參數定義,AI 模型會根據使用者的需求判斷應該呼叫哪個工具,並自動組裝適當的參數。
舉例來說,一個 GitHub MCP 伺服器可能會暴露以下工具:create_issue(建立新的 Issue)、list_pull_requests(列出 Pull Request)、merge_branch(合併分支)。當使用者對 AI 助理說「幫我在 my-project 這個 repo 建立一個關於登入頁面 bug 的 Issue」時,AI 模型會自動選擇 create_issue 這個工具,填入適當的 repository 名稱、標題和描述,然後透過 MCP 協議將這個呼叫傳送到 GitHub MCP 伺服器執行。
工具的設計哲學是「模型控制」— AI 模型擁有主動權,可以根據上下文和使用者意圖自主決定是否呼叫工具以及如何使用工具。這與傳統的 API 呼叫不同,傳統方式需要開發者在程式碼中明確指定何時呼叫哪個 API,而 MCP 的工具機制讓 AI 模型能夠靈活地在對話過程中動態調用功能。
資源(Resources)
資源代表 AI 模型可以存取的結構化資料。與工具不同,資源是唯讀的 — AI 模型可以讀取資源的內容,但不會對資料來源進行任何修改。這種設計確保了資料存取的安全性,同時讓 AI 模型能夠獲得完成任務所需的上下文資訊。
資源的運作方式類似於 REST API 中的 GET 端點。每個資源都有一個唯一的 URI(統一資源識別符),AI 模型可以透過這個 URI 請求特定的資料。例如,一個檔案系統 MCP 伺服器可能會將每個檔案暴露為一個資源,URI 格式為 file:///path/to/document.txt。AI 模型在需要參考某個檔案內容時,就可以透過對應的 URI 讀取它。
資源的設計哲學是「應用程式控制」— 由 MCP 主機(Host)決定哪些資源要提供給 AI 模型。這意味著應用程式可以根據安全政策和使用者權限,精確控制 AI 模型能夠存取哪些資料,避免敏感資訊被不當存取。
提示範本(Prompts)
提示範本是三種原語中最容易被忽略、但實務上極其實用的一種。它允許 MCP 伺服器預先定義一組互動範本,引導 AI 模型以特定的方式處理某類任務。
例如,一個程式碼審查的提示範本可能會指示 AI 模型:先讀取指定的程式碼檔案(使用資源),然後按照特定的檢查清單逐項審查,最後以固定的格式輸出審查結果。這種範本化的做法確保了一致性和品質,同時也降低了使用者的學習成本 — 使用者不需要自己設計複雜的提示詞,只需選擇適當的範本即可。
提示範本的設計哲學是「使用者控制」— 最終是由使用者決定要啟用哪個範本。這讓使用者對 AI 的行為模式有更精確的掌控力。
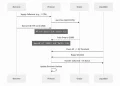
MCP 架構詳解
MCP 的架構設計遵循客戶端-伺服器模式,但加入了「主機」這個額外的層級,形成一個清晰的四層結構。理解這個架構是掌握 MCP 運作方式的關鍵。
整體架構的資料流向如下:
MCP 主機(Host)→ MCP 客戶端(Client)→ MCP 伺服器(Server)→ 外部服務(External Service)
以下逐一說明每個層級的角色與責任。
MCP 主機(Host)
主機是使用者直接互動的應用程式,也是整個 MCP 架構的最外層。常見的主機包括 Claude Desktop 桌面應用程式、VS Code 等程式碼編輯器、或是任何內建 AI 功能的應用程式。主機的主要職責是管理使用者介面、處理 AI 模型的推理過程,以及協調一個或多個 MCP 客戶端的運作。
重要的是,主機同時也是安全的最後一道防線。它負責執行使用者的權限控制政策,決定哪些 MCP 伺服器可以被連接、哪些工具可以被呼叫、哪些資源可以被存取。在許多實作中,主機會在 AI 模型要求執行某個工具之前,先向使用者顯示確認對話框,確保使用者知悉並同意即將執行的動作。
MCP 客戶端(Client)
客戶端是嵌入在主機應用程式內部的通訊模組,負責與 MCP 伺服器建立和維護連線。每個客戶端通常對應一個 MCP 伺服器,維持一對一的連線關係。客戶端處理協議層級的細節,包括訊息的序列化與反序列化、連線的生命週期管理,以及錯誤處理。
客戶端的存在讓主機不需要直接處理與 MCP 伺服器通訊的複雜性。主機只需要透過一個簡潔的內部介面告訴客戶端「我需要呼叫這個工具」或「我需要讀取這個資源」,客戶端就會自動處理後續的通訊流程。
MCP 伺服器(Server)
伺服器是 MCP 架構中連接 AI 世界與外部系統世界的橋樑。每個 MCP 伺服器都專注於暴露特定外部服務的功能,將該服務的 API 轉換為 MCP 協議格式的工具、資源和提示範本。
例如,一個 Slack MCP 伺服器會將 Slack 的各種 API 功能封裝為 MCP 工具(如 send_message、list_channels)和資源(如特定頻道的訊息歷史)。AI 模型不需要知道 Slack API 的具體格式和認證方式,它只需要透過標準的 MCP 協議與 Slack MCP 伺服器溝通,伺服器會負責將 MCP 請求轉譯為 Slack API 呼叫。
MCP 伺服器可以是本地執行的程式,也可以是遠端部署的服務。本地伺服器通常透過標準輸入輸出(stdio)與客戶端通訊,適合存取本地檔案系統或執行本地工具的場景。遠端伺服器則透過 HTTP 搭配 Server-Sent Events(SSE)通訊,適合需要存取雲端服務或需要多使用者共享的場景。
外部服務(External Service)
外部服務是整個鏈條的最末端,包括各種 API、資料庫、檔案系統、SaaS 平台等。這些服務本身不需要知道 MCP 的存在 — MCP 伺服器負責處理所有的協議轉換工作。這意味著任何現有的服務,只要有人為它建置一個 MCP 伺服器,就能立即被整合進 MCP 生態系中,而服務本身不需要做任何修改。
多伺服器並行運作
在實際使用中,一個 MCP 主機通常會同時連接多個 MCP 伺服器。例如,一位開發者在 Claude Desktop 中可能同時啟用了 GitHub 伺服器、檔案系統伺服器和資料庫伺服器。當使用者提出一個複雜的需求,如「幫我查看最新的 Pull Request,讀取相關的程式碼變更,然後將審查結果寫入資料庫」,AI 模型可以跨多個 MCP 伺服器協調操作,先從 GitHub 伺服器取得 PR 資訊,再從檔案系統伺服器讀取程式碼,最後透過資料庫伺服器寫入審查結果。
這種多伺服器並行的能力,是 MCP 架構設計中一個重要的優勢。它讓 AI 助理真正成為一個能夠跨系統操作的工作夥伴,而不是只能與單一服務互動的單功能工具。
支援 MCP 的主要應用程式
自 2024 年 11 月 MCP 發表以來,愈來愈多 AI 應用程式和開發工具宣布支援這項協議。以下整理截至目前的主要支援清單。
| 應用程式 | 類型 | MCP 支援方式 | 說明 |
|---|---|---|---|
| Claude Desktop | AI 桌面助理 | 原生支援 | Anthropic 官方桌面應用程式,最早支援 MCP 的主機之一 |
| Claude Code | AI 命令列工具 | 原生支援 | Anthropic 的終端機 AI 助理,支援透過 MCP 連接各種開發工具 |
| VS Code(Copilot) | 程式碼編輯器 | 透過 GitHub Copilot 擴充功能 | 微軟的主力編輯器,透過 Copilot Agent 模式支援 MCP |
| JetBrains IDE | 程式碼編輯器 | 內建 AI Assistant 支援 | IntelliJ IDEA、PyCharm 等 JetBrains 系列 IDE |
| Cursor | AI 程式碼編輯器 | 原生支援 | 以 AI 輔助開發為核心的編輯器,早期即導入 MCP 支援 |
| Windsurf | AI 程式碼編輯器 | 原生支援 | 由 Codeium 開發的 AI 編輯器 |
| Zed | 程式碼編輯器 | 原生支援 | 高效能編輯器,內建 AI 功能支援 MCP |
| Sourcegraph Cody | AI 程式碼助理 | 原生支援 | 程式碼搜尋與理解平台的 AI 助理 |
值得注意的是,這份清單持續擴大中。MCP 作為開源標準,任何開發者或企業都可以在自己的產品中加入 MCP 支援。這種開放性正是 MCP 能夠快速獲得採用的關鍵因素之一。
從這份清單可以觀察到一個趨勢:程式碼編輯器和開發工具是 MCP 最早且最積極的採用者。這並不意外,因為軟體開發本身就是一個高度依賴多系統協作的工作場景 — 開發者日常需要在版本控制、專案管理、文件系統、資料庫之間頻繁切換,MCP 恰好能夠將這些工具無縫整合到 AI 助理的能力範圍中。
熱門預建 MCP 伺服器
MCP 生態系的一大優勢在於,社群和官方已經建置了大量預建的 MCP 伺服器,覆蓋了最常見的使用場景。開發者和使用者不需要從零開始建置,直接安裝和設定就能使用。
| MCP 伺服器 | 對應服務 | 主要功能 |
|---|---|---|
| GitHub MCP Server | GitHub | 管理 Repository、Issue、Pull Request、Actions、搜尋程式碼 |
| Slack MCP Server | Slack | 發送與讀取訊息、管理頻道、搜尋對話紀錄 |
| Google Drive MCP Server | Google Drive | 搜尋、讀取和管理 Google Drive 中的檔案與文件 |
| PostgreSQL MCP Server | PostgreSQL | 查詢資料庫、執行 SQL 指令、檢視資料表結構 |
| SQLite MCP Server | SQLite | 操作本地 SQLite 資料庫,適合開發和測試環境 |
| Filesystem MCP Server | 本地檔案系統 | 讀寫檔案、目錄操作、檔案搜尋,限定在指定目錄範圍內 |
| Brave Search MCP Server | Brave Search | 透過 Brave Search API 執行網頁搜尋 |
| Puppeteer MCP Server | 瀏覽器自動化 | 控制無頭瀏覽器,擷取網頁內容、截圖、自動化表單操作 |
| Git MCP Server | Git 版本控制 | 查看 commit 紀錄、diff、分支管理等 Git 操作 |
| Memory MCP Server | 知識圖譜 | 建立和查詢持久化的知識圖譜,讓 AI 模型具備長期記憶 |
這些預建伺服器覆蓋了幾個主要類別。開發工具類包含 GitHub、Git 等,讓 AI 助理直接參與軟體開發流程。通訊協作類如 Slack,讓 AI 助理可以讀取和發送團隊訊息。資料存取類如各種資料庫伺服器和檔案系統伺服器,讓 AI 助理能夠查詢和管理資料。資訊檢索類如搜尋引擎和瀏覽器自動化伺服器,讓 AI 助理可以從網路上獲取最新資訊。
除了上述列出的伺服器之外,社群還持續開發新的 MCP 伺服器。在 GitHub 上可以找到涵蓋 Notion、Jira、Linear、Sentry、Docker、Kubernetes 等眾多服務的 MCP 伺服器。這種社群驅動的生態系發展模式,確保了 MCP 的覆蓋範圍能夠隨著需求快速擴展。
快速入門 — 以 Claude Desktop 為例
對於想要立即體驗 MCP 的使用者來說,Claude Desktop 搭配預建 MCP 伺服器是最簡單的入門方式。以下以連接檔案系統 MCP 伺服器為例,說明完整的設定步驟。
步驟一:安裝 Claude Desktop
前往 Anthropic 官方網站下載 Claude Desktop 桌面應用程式。安裝完成後,使用 Anthropic 帳號登入。確認應用程式版本支援 MCP 功能 — 通常在設定頁面中可以看到 MCP 相關的選項。
步驟二:安裝 MCP 伺服器
大多數 MCP 伺服器都以 npm 套件或 Python 套件的形式發布。以檔案系統伺服器為例,可以透過 npm 安裝:
npm install -g @modelcontextprotocol/server-filesystem
如果偏好使用 Python 版本,也可以透過 pip 安裝對應的套件。
步驟三:設定 Claude Desktop
Claude Desktop 的 MCP 設定檔位於以下路徑:
# macOS ~/Library/Application Support/Claude/claude_desktop_config.json # Windows %APPDATA%Claudeclaude_desktop_config.json
開啟設定檔,加入 MCP 伺服器的設定。以下是一個連接檔案系統伺服器的設定範例:
"mcpServers":
"filesystem":
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/username/Documents",
"/Users/username/Projects"
]
這個設定告訴 Claude Desktop:啟動一個名為 filesystem 的 MCP 伺服器,使用 npx 執行 @modelcontextprotocol/server-filesystem 套件,並且授權 AI 模型存取 /Users/username/Documents 和 /Users/username/Projects 這兩個目錄。
步驟四:重新啟動並驗證
儲存設定檔後,重新啟動 Claude Desktop。如果設定正確,在對話介面的輸入框附近應該會出現一個工具圖示,點擊後可以看到檔案系統伺服器暴露的工具清單,包括 read_file、write_file、list_directory 等。
此時就可以開始測試了。嘗試輸入「列出我 Documents 目錄下的所有檔案」,Claude 應該會呼叫 list_directory 工具並回傳結果。或者輸入「讀取 Projects 目錄下的 README.md 檔案」,Claude 就會透過 read_file 工具讀取並顯示檔案內容。
新增更多伺服器
同一個設定檔中可以加入多個 MCP 伺服器。例如,想要同時連接 GitHub 和資料庫:
"mcpServers":
"filesystem":
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/Users/username/Projects"]
,
"github":
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env":
"GITHUB_PERSONAL_ACCESS_TOKEN": "ghp_xxxxxxxxxxxx"
,
"postgres":
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-postgres", "postgresql://localhost/mydb"]
每個伺服器可以有自己的執行指令、參數和環境變數設定。GitHub 伺服器需要提供 Personal Access Token 進行認證,資料庫伺服器則需要提供連線字串。
開發自己的 MCP 伺服器
當預建的 MCP 伺服器無法滿足需求時,開發者可以自行建置 MCP 伺服器。MCP 提供了 Python 和 TypeScript 兩種語言的官方 SDK,大幅降低了開發門檻。
使用 Python SDK
Python SDK 適合資料科學家、後端工程師以及熟悉 Python 生態系的開發者。以下是一個簡單的天氣查詢 MCP 伺服器範例:
from mcp.server import Server
from mcp.types import Tool, TextContent
import httpx
server = Server("weather-server")
@server.list_tools()
async def list_tools():
return [
Tool(
name="get_weather",
description="取得指定城市的目前天氣資訊",
inputSchema=
"type": "object",
"properties":
"city":
"type": "string",
"description": "城市名稱,例如 Taipei"
,
"required": ["city"]
)
]
@server.call_tool()
async def call_tool(name: str, arguments: dict):
if name == "get_weather":
city = arguments["city"]
# 呼叫天氣 API 取得資料
async with httpx.AsyncClient() as client:
response = await client.get(
f"https://api.weatherapi.com/v1/current.json?q=city"
)
data = response.json()
return [TextContent(
type="text",
text=f"city 目前溫度:data['current']['temp_c']°C"
)]
if __name__ == "__main__":
import asyncio
from mcp.server.stdio import stdio_server
async def main():
async with stdio_server() as (read, write):
await server.run(read, write)
asyncio.run(main())
這個範例展示了 MCP 伺服器開發的基本結構。透過 @server.list_tools() 裝飾器定義伺服器提供的工具清單,透過 @server.call_tool() 裝飾器實作工具被呼叫時的處理邏輯。整個流程清晰直觀,一個有基本 Python 經驗的開發者可以在幾小時內完成一個功能完整的 MCP 伺服器。
使用 TypeScript SDK
TypeScript SDK 適合前端開發者和 Node.js 後端開發者。以下是同樣功能的 TypeScript 版本骨架:
import Server from "@modelcontextprotocol/sdk/server/index.js";
import StdioServerTransport from "@modelcontextprotocol/sdk/server/stdio.js";
import
CallToolRequestSchema,
ListToolsRequestSchema,
from "@modelcontextprotocol/sdk/types.js";
const server = new Server(
name: "weather-server", version: "1.0.0" ,
capabilities: tools:
);
server.setRequestHandler(ListToolsRequestSchema, async () => (
tools: [
name: "get_weather",
description: "取得指定城市的目前天氣資訊",
inputSchema:
type: "object",
properties:
city: type: "string", description: "城市名稱" ,
,
required: ["city"],
,
,
],
));
server.setRequestHandler(CallToolRequestSchema, async (request) =>
if (request.params.name === "get_weather")
const city = request.params.arguments?.city;
const response = await fetch(
`https://api.weatherapi.com/v1/current.json?q=$city`
);
const data = await response.json();
return
content: [
type: "text",
text: `$city 目前溫度:$data.current.temp_c°C`,
,
],
;
throw new Error("Unknown tool");
);
const transport = new StdioServerTransport();
await server.connect(transport);
兩種 SDK 的設計理念一致,只是語法風格配合各自語言的慣例。開發者可以根據自己的技術背景和專案需求選擇合適的 SDK。
暴露資源
除了工具之外,MCP 伺服器也可以暴露資源。資源的定義方式與工具類似,開發者需要實作 list_resources 和 read_resource 兩個處理函式。資源讓 AI 模型能夠主動瀏覽和讀取伺服器管理的資料,而不僅限於透過工具呼叫來操作。
發布與分享
完成開發後,MCP 伺服器可以發布到 npm(TypeScript 版本)或 PyPI(Python 版本),供其他使用者安裝使用。Anthropic 也維護了一個官方的 MCP 伺服器登錄冊,開發者可以將自己的伺服器提交到登錄冊,讓更多人發現和使用。
MCP 與 Function Calling 的差異
許多接觸過 OpenAI Function Calling 或其他 AI 工具呼叫機制的讀者,可能會疑惑 MCP 與這些既有機制之間的差異。這是一個重要的釐清,因為兩者雖然表面上都是「讓 AI 呼叫工具」,但在設計層級和解決的問題上有根本性的不同。
Function Calling 是模型層級的能力
Function Calling(函式呼叫,也稱為 Tool Use)是大型語言模型本身提供的一項能力。當開發者在 API 請求中定義一組函式的名稱、描述和參數格式,模型會根據使用者的輸入判斷是否需要呼叫某個函式,並輸出結構化的呼叫指令。
然而,Function Calling 本身並不執行任何操作。模型只是產出一個「我想呼叫這個函式,參數是這些」的結構化輸出,實際的函式執行必須由開發者自行在應用程式的程式碼中處理。模型不知道函式執行的結果,除非開發者將結果回傳給模型進行下一輪對話。
MCP 是應用層級的標準協議
MCP 運作在完全不同的層級。它不是模型的能力,而是應用程式之間通訊的標準。MCP 定義了 AI 主機應用程式如何發現、連接和呼叫外部服務的完整流程,包括服務發現(這個 MCP 伺服器提供哪些工具和資源)、通訊傳輸(如何在主機和伺服器之間傳遞訊息)、安全控制(權限管理和使用者同意機制),以及生命週期管理(連線的建立、維護和斷開)。
兩者的關係
MCP 和 Function Calling 並非互斥的替代方案,而是互補的不同層級。在實際運作中,MCP 主機內部很可能使用 Function Calling 作為 AI 模型與 MCP 客戶端之間的溝通方式。流程大致如下:MCP 客戶端連接到 MCP 伺服器後,取得可用的工具清單。主機將這些工具以 Function Calling 格式註冊給 AI 模型。使用者提出需求後,AI 模型透過 Function Calling 產出工具呼叫指令。主機接收到呼叫指令,透過 MCP 客戶端將請求傳送給對應的 MCP 伺服器。MCP 伺服器執行操作後回傳結果,主機再將結果回饋給 AI 模型。
換句話說,Function Calling 處理的是「AI 模型如何表達它想呼叫一個工具」,而 MCP 處理的是「這個工具呼叫如何被路由到正確的外部服務並實際執行」。
| 比較面向 | Function Calling | MCP |
|---|---|---|
| 運作層級 | 模型層級 | 應用程式層級 |
| 定義方 | 應用程式開發者在 API 請求中定義 | MCP 伺服器定義並動態暴露 |
| 工具發現 | 靜態,需事先在程式碼中定義 | 動態,客戶端在連線時自動從伺服器取得 |
| 執行方式 | 開發者自行在應用程式中實作 | MCP 伺服器負責執行,結果透過協議回傳 |
| 可重用性 | 每個應用程式各自實作 | 一個 MCP 伺服器可供所有 MCP 主機使用 |
| 標準化程度 | 各模型提供商格式不同 | 統一的開源標準 |
| 跨模型相容 | 通常綁定特定模型 API | 與模型無關,任何支援 MCP 的主機都可使用 |
MCP 的安全機制
作為一個讓 AI 模型與外部系統互動的協議,安全性是 MCP 設計中的核心考量。MCP 在多個層面實作了安全控制機制。
在使用者同意層面,MCP 主機在 AI 模型要求執行工具呼叫時,通常會向使用者顯示確認提示。使用者可以在每次呼叫前審視 AI 模型要做什麼,並決定是否允許。這個機制確保了人類始終保持對 AI 行為的控制權。
在存取控制層面,MCP 伺服器可以限制可存取的範圍。例如,檔案系統伺服器可以設定只允許存取特定目錄,資料庫伺服器可以限制只能執行唯讀查詢。這種最小權限原則(Principle of Least Privilege)降低了意外操作或惡意利用的風險。
在認證層面,連接需要認證的外部服務(如 GitHub、Slack)時,MCP 伺服器通常透過環境變數接收 API 金鑰或存取權杖。這些憑證由使用者在設定檔中提供,不會經過 AI 模型或 MCP 主機,確保了認證資訊的安全隔離。
在傳輸安全層面,遠端 MCP 伺服器的通訊通常透過 HTTPS 加密。本地伺服器透過 stdio 通訊,資料不經過網路,安全性更高。
常見問題
MCP 是 Anthropic 專屬的技術嗎
不是。MCP 是一個完全開源的標準,任何人都可以自由使用、實作和貢獻。雖然 MCP 由 Anthropic 提出並主導初期開發,但它被設計為一個廠商中立的協議。任何 AI 模型提供商、任何應用程式開發者都可以在自己的產品中實作 MCP 支援。事實上,目前已有多個非 Anthropic 的產品支援 MCP,包括微軟的 VS Code(透過 Copilot)和多個獨立開發的 AI 編輯器。MCP 的規格文件和參考實作都在 GitHub 上公開,遵循開源授權條款。
使用 MCP 需要付費嗎
MCP 本身作為一個開源協議是完全免費的。官方提供的 SDK(Python 和 TypeScript 版本)以及大部分預建的 MCP 伺服器也都是免費的開源軟體。不過,使用 MCP 的過程中可能涉及的費用取決於其他因素。例如,如果透過 Claude Desktop 使用 MCP,則需要有 Claude 的使用額度。如果 MCP 伺服器連接的外部服務(如某些 API)有自己的收費標準,那些費用仍然適用。但 MCP 協議本身不收取任何費用。
MCP 伺服器可以同時被多個主機使用嗎
取決於伺服器的類型。本地 MCP 伺服器(透過 stdio 通訊)通常是由主機啟動的獨立程序,每個主機會啟動自己的伺服器實例,因此不會有共享的問題。遠端 MCP 伺服器(透過 HTTP/SSE 通訊)則可以被設計為支援多個客戶端同時連接,類似於傳統的 Web 服務。在這種情況下,多個不同的主機應用程式可以同時連接到同一個遠端 MCP 伺服器。
MCP 支援哪些程式語言
目前 Anthropic 官方提供 Python 和 TypeScript 兩種語言的 MCP SDK。不過,由於 MCP 是一個基於 JSON-RPC 的通訊協議,理論上任何能夠處理 JSON 和標準輸入輸出的程式語言都可以用來建置 MCP 伺服器。社群已經出現了 Rust、Go、Java、C# 等語言的非官方 SDK 或參考實作。選擇哪種語言主要取決於開發者的熟悉程度和專案需求。
MCP 能用在企業內部系統嗎
可以,而且這正是 MCP 最有價值的應用場景之一。企業可以為自己的內部系統(如內部 API、私有資料庫、自建工具)建置 MCP 伺服器,讓員工透過支援 MCP 的 AI 助理直接存取這些系統。由於 MCP 伺服器可以在本地或企業內網部署,資料不需要經過外部服務,能夠滿足企業對資料安全的要求。許多企業已經開始探索這種模式,將 MCP 作為 AI 輔助工作流程的基礎架構。
MCP 與 LangChain 或 LlamaIndex 等框架有什麼關係
LangChain 和 LlamaIndex 是 AI 應用程式開發框架,它們提供了建構 AI 應用程式的各種元件和抽象層。MCP 則是一個通訊協議標準,專注於定義 AI 應用程式與外部服務之間的互動方式。兩者並不衝突,反而可以搭配使用。例如,一個基於 LangChain 建構的 AI 應用程式可以透過 MCP 客戶端連接到各種 MCP 伺服器,藉此獲得存取外部工具和資料的能力。MCP 可以被視為這些框架的「連接層」補充,讓它們能夠更容易地整合外部服務。
如何確保 MCP 伺服器的安全性
建置和使用 MCP 伺服器時,有幾項安全實踐值得遵循。首先,只安裝來自可信來源的 MCP 伺服器,檢查其原始碼和社群評價。其次,遵循最小權限原則 — 只授予 MCP 伺服器完成任務所需的最低限度權限。例如,如果 AI 只需要讀取檔案,就不要授予寫入權限。第三,妥善管理認證憑證 — 使用環境變數存放 API 金鑰,不要將憑證寫在設定檔中或提交到版本控制系統。第四,定期更新 MCP 伺服器版本,以獲得安全修補。最後,在企業環境中,建議對 MCP 伺服器進行安全審計,確保它們符合組織的安全政策。
MCP 的未來展望
MCP 的推出雖然時間不長,但已經展現出成為 AI 應用程式標準互動層的潛力。從技術演進的角度來看,幾個發展方向值得關注。
在協議層面,MCP 仍在持續演進。未來的版本可能會加入更完善的串流(Streaming)支援,讓長時間執行的操作能夠即時回傳進度。認證和授權機制也在進一步標準化,特別是針對遠端 MCP 伺服器的場景。此外,多模態資料(如圖片和音訊)的傳輸支援也在規劃中。
在生態系層面,隨著愈來愈多的 AI 應用程式和外部服務加入 MCP 支援,整個生態系的網路效應將不斷加強。當大多數 AI 應用程式都支援 MCP、大多數常用服務都有對應的 MCP 伺服器時,MCP 將成為 AI 應用開發的事實標準,如同 HTTP 之於 Web 開發。
在應用場景層面,MCP 將推動 AI 助理從「對話式工具」演變為「工作流程協調者」。當 AI 模型能夠無縫存取使用者的所有工作工具和資料時,它就能夠理解完整的工作脈絡,提供更精準、更有價值的協助。這對於企業生產力提升的潛力是巨大的。
MCP 的成功與否最終取決於生態系的健康程度。一個好的標準需要廣泛的採用、持續的維護和社群的積極參與。從目前的發展態勢來看,MCP 已經跨出了穩健的第一步,接下來的關鍵在於能否維持這個動能,吸引更多的開發者和企業加入。
風險提示
加密貨幣投資具有高度風險,其價格可能波動劇烈,您可能損失全部本金。請謹慎評估風險。